
str.contains : 엑셀에서 'Ctrl + F'한 것과 동일하다
파이썬 re패키지 : 엑셀에서 '열'을 선택한 후 'Ctrl + F'한 후 '모두 바꾸기' 한 것과 동일한 결과이다.
예제파일
# 환경구축
import numpy as np
import pandas as pd
import re
# 예제파일 불러오기
# 예제파일은 작업하는 파이썬과 같이 경로에 있어야 한다.
ipo2021_df = pd.read_excel('IPO_list.xlsx', sheet_name='2021')
ipo2021_df
# 데이터프레임 정보조회
# 신규상장일 칼럼을 제외하고 데이터는 모두 object 타입이다.
print(ipo2021_df.info(), ipo2021_df.isna().sum())
pd.set_option('display.max_rows', None) # 데이터프레임의 '행' 모두 나오게 하기
ipo2021_df.sort_values('시초/공모(%)', ascending=False) # '시초/공모(%) 높은 순서로 출력하기
ipo2021_df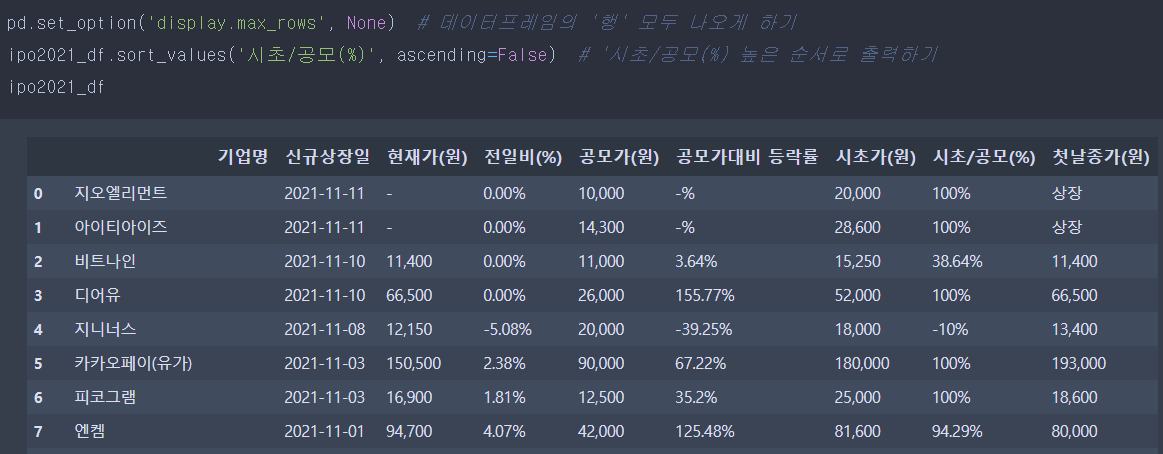
# value와 dtype 확인
print(ipo2021_df['시초/공모(%)'][0], type(ipo2021_df['시초/공모(%)'][0]))
'시초/공모(%)' 높은 순서로 출력하려고 해도, 해당 데이터의 타입은 문자열(string)이기 때문에 정렬(sort_values)이 의도한대로 되지 않는다. 따라서 '시초/공모(%)' 칼럼의 데이터 타입을 의도한대로 정렬이 될 수 있는 '숫자(int, float)'타입으로 바꿔야 한다.
데이터 찾기
가끔 데이터를 입력할 때, 숫자 0을 작대기 -로 표시하는 사람도 있다. 이 경우 데이터가 존재하기 때문에 결측치로 확인되지 않는다. 다만, 해당 문자(-)가 존재하기 때문에 숫자형(numeric type)으로 변경하려는 경우 ValueError: invalid literal for int() with base 10: '-\xa0' 가 발생한다.
오류를 해결하기 위해서는 작대기(-) 등을 데이터 모델링 전에 제거/변환해야 한다. 이 작업을 '데이터 전처리'라 부른다. 아래 코드를 실행하면 '1' 이 나온다. 즉, 해당 칼럼에 작대기(-)가 포함된 데이터(행)가 1개 있음을 알 수 있다. 해당 행(row)을 지우거나 0과 같은 숫자로 대체한다.
# 데이터프레임명['칼럼명'].str.contains('찾을문자').sum()
ipo2021_df['첫날종가(원)'].str.contains('-').sum()
# 작대기(-)를 공백으로 바꾼 후, 작대기가 포함된 행 조회
ipo2021_df['현재가(원)'] = ipo2021_df['현재가(원)'].map(lambda x : re.sub(r'-','',x))
ipo2021_df['공모가(원)'] = ipo2021_df['공모가(원)'].map(lambda x : re.sub(r'-','',x))
ipo2021_df['시초가(원)'] = ipo2021_df['시초가(원)'].map(lambda x : re.sub(r'-','',x))
ipo2021_df['첫날종가(원)'] = ipo2021_df['첫날종가(원)'].map(lambda x : re.sub(r'-','',x))
ipo2021_df['첫날종가(원)'].str.contains('-').sum()
데이터 바꾸기
# 해당 칼럼의 '%'를 제거하거나 치환한다.
# map함수와 re함수를 이용하여 문자열(%)을 공백('')으로 바꾼다
ipo2021_df['시초/공모(%)'] = ipo2021_df['시초/공모(%)'].map(lambda x : re.sub(r'%', '', x))
ipo2021_df
# value와 dtype 확인
print(ipo2021_df['시초/공모(%)'][0], type(ipo2021_df['시초/공모(%)'][0]))
간단하게 re함수 쓰는법은 아래와 같다.
# re는 regular expression의 약자이다. 입력한 패턴과 일치하는 문자열을 '검색', '치환', '제거'하는 기능이 있다.
import re # re패키지 호출
a = 'abc\n' # \n 은 문자열에서 줄바꿈을 의미하므로 출력하지 않는다
print(a)
b = r'abc\n' # '문자열' 앞에 r이 붙는 경우, 해당 문자열을 그대로 반환
print(b)
ipo2021_df["시초/공모(%)"] = ipo2021_df["시초/공모(%)"].astype('float') # dtype (str >> float)
ipo2021_df.sort_values("시초/공모(%)", ascending=False, inplace=True) # ipo2021_df 정렬하기
ipo2021_df
# 시초가가 공모가의 두배를 형성한 종목선별
따블 = ipo2021_df.loc[ipo2021_df["시초/공모(%)"] == 100]
따블.reset_index(drop=True, inplace=True)
따블
# 2021년 상장한 주식종목중 첫날 시초가 두배를 형성한 종목이 차지하는 비율
시초가_2배 = len(따블.index) / len(ipo2021_df.index) * 100
print(f'{시초가_2배:.2f}%')
'Develop > Python' 카테고리의 다른 글
| [Python] 요일 구하기 (datetime) (0) | 2022.06.18 |
|---|---|
| [Python] 반올림, 올림, 내림, 소수점 버림 (round, ceil, floor, trunc) (0) | 2022.06.18 |
| [Python] 나누기, 몫, 나머지 ( / , // , % , divmod ) (0) | 2022.06.18 |
| [Python] 데이터 선택하기 (인덱싱 / 슬라이싱) (0) | 2022.03.19 |
| [Python] 출력형식 %d %01d %02d %s %f (0) | 2022.03.09 |

